publications
publications by year in reversed chronological order.
2024
-
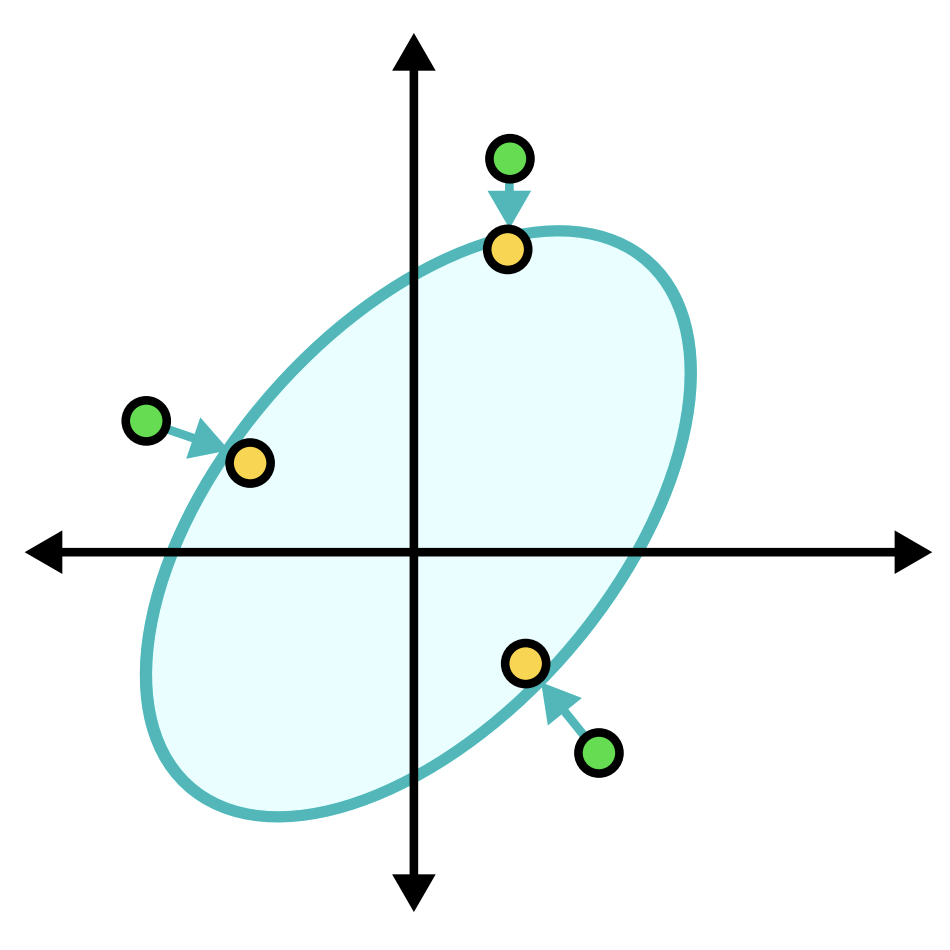 Steering Large Language Models using Conceptors: Improving Addition-Based Activation EngineeringJoris Postmus, and Steven AbreuIn Neural Information Processing Systems (NeurIPS) 2024 - MINT Workshop, 2024Presented at NeurIPS workshop MINT
Steering Large Language Models using Conceptors: Improving Addition-Based Activation EngineeringJoris Postmus, and Steven AbreuIn Neural Information Processing Systems (NeurIPS) 2024 - MINT Workshop, 2024Presented at NeurIPS workshop MINTLarge language models have transformed AI, yet reliably controlling their outputs remains a challenge. This paper explores activation engineering, where outputs of pre-trained LLMs are controlled by manipulating their activations at inference time. Unlike traditional methods using a single steering vector, we introduce conceptors - mathematical constructs that represent sets of activation vectors as ellipsoidal regions. Conceptors act as soft projection matrices and offer more precise control over complex activation patterns. Our experiments demonstrate that conceptors outperform traditional methods across multiple steering tasks. We further use Boolean operations on conceptors for combined steering goals that empirically outperform additively combining steering vectors on a set of tasks. These results highlight conceptors as a promising tool for more effective steering of LLMs.
@inproceedings{postmus2024steering, title = {Steering Large Language Models using Conceptors: Improving Addition-Based Activation Engineering}, author = {Postmus, Joris and Abreu, Steven}, year = {2024}, eprint = {2410.16314}, archiveprefix = {arXiv}, primaryclass = {cs.NE}, note = {Presented at NeurIPS workshop MINT}, url = {https://openreview.net/forum?id=gyAnAq16HC}, booktitle = {Neural Information Processing Systems (NeurIPS) 2024 - MINT Workshop}, } -
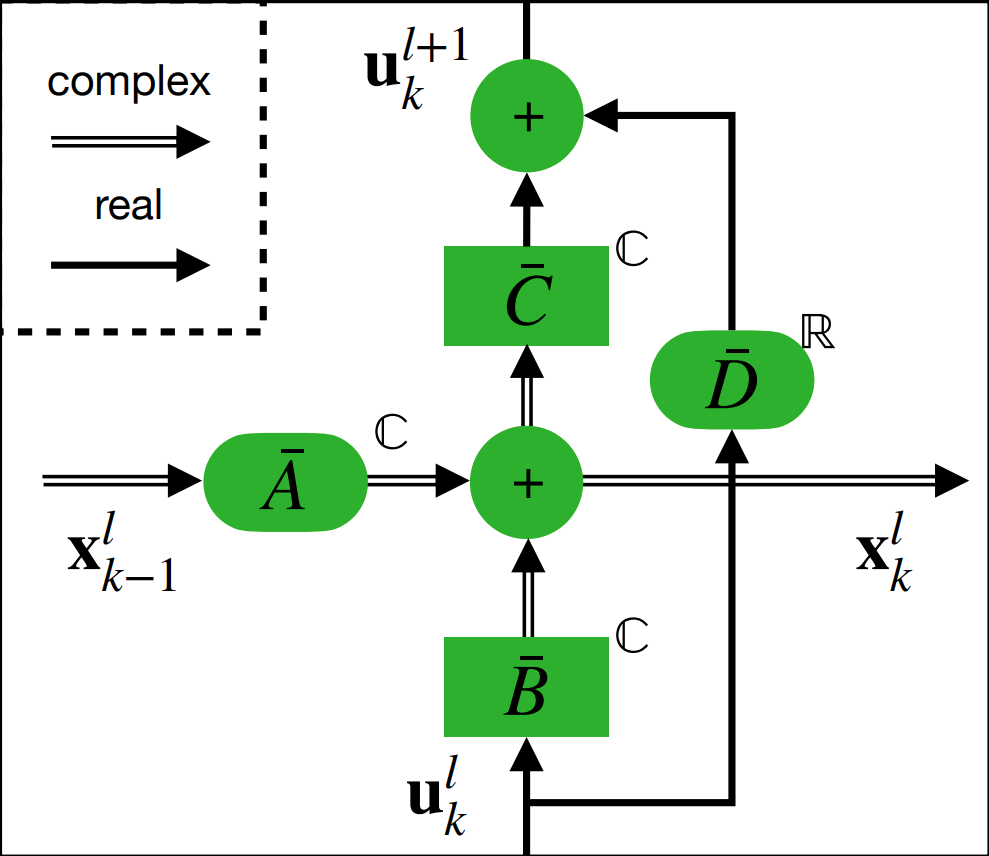 Q-S5: Towards Quantized State Space ModelsSteven Abreu*, Jens E. Pedersen*, Kade M. Heckel*, and 1 more authorIn International Conference on Machine Learning (ICML) 2024 - NGSM workshop, 2024Presented at ICML workshop NGSM
Q-S5: Towards Quantized State Space ModelsSteven Abreu*, Jens E. Pedersen*, Kade M. Heckel*, and 1 more authorIn International Conference on Machine Learning (ICML) 2024 - NGSM workshop, 2024Presented at ICML workshop NGSMIn the quest for next-generation sequence modeling architectures, State Space Models (SSMs) have emerged as a potent alternative to transformers, particularly for their computational efficiency and suitability for dynamical systems. This paper investigates the effect of quantization on the S5 model to understand its impact on model performance and to facilitate its deployment to edge and resource-constrained platforms. Using quantization-aware training (QAT) and post-training quantization (PTQ), we systematically evaluate the quantization sensitivity of SSMs across different tasks like dynamical systems modeling, Sequential MNIST (sMNIST) and most of the Long Range Arena (LRA). We present fully quantized S5 models whose test accuracy drops less than 1% on sMNIST and most of the LRA. We find that performance on most tasks degrades significantly for recurrent weights below 8-bit precision, but that other components can be compressed further without significant loss of performance. Our results further show that PTQ only performs well on language-based LRA tasks whereas all others require QAT. Our investigation provides necessary insights for the continued development of efficient and hardware-optimized SSMs.
@inproceedings{abreu2024qs5, title = {Q-S5: Towards Quantized State Space Models}, author = {Abreu, Steven and Pedersen, Jens E. and Heckel, Kade M. and Pierro, Alessandro}, year = {2024}, eprint = {2406.09477}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, note = {Presented at ICML workshop NGSM}, booktitle = {International Conference on Machine Learning (ICML) 2024 - NGSM workshop}, } -
 Mamba-PTQ: Outlier Channels in Recurrent Large Language ModelsAlessandro Pierro*, and Steven Abreu*In International Conference on Machine Learning (ICML) 2024 - ES-FOMO-II workshop, 2024Presented at ICML workshop ES-FOMO-II
Mamba-PTQ: Outlier Channels in Recurrent Large Language ModelsAlessandro Pierro*, and Steven Abreu*In International Conference on Machine Learning (ICML) 2024 - ES-FOMO-II workshop, 2024Presented at ICML workshop ES-FOMO-IIModern recurrent layers are emerging as a promising path toward edge deployment of foundation models, especially in the context of large language models (LLMs). Compressing the whole input sequence in a finite-dimensional representation enables recurrent layers to model long-range dependencies while maintaining a constant inference cost for each token and a fixed memory requirement. However, the practical deployment of LLMs in resource-limited environments often requires further model compression, such as quantization and pruning. While these techniques are well-established for attention-based models, their effects on recurrent layers remain underexplored. In this preliminary work, we focus on post-training quantization for recurrent LLMs and show that Mamba models exhibit the same pattern of outlier channels observed in attention-based LLMs. We show that the reason for the difficulty of quantizing SSMs is caused by activation outliers, similar to those observed in transformer-based LLMs. We report baseline results for post-training quantization of Mamba that do not take into account the activation outliers and suggest first steps for outlier-aware quantization.
@inproceedings{pierro2024mambaptqoutlierchannelsrecurrent, title = {Mamba-PTQ: Outlier Channels in Recurrent Large Language Models}, author = {Pierro, Alessandro and Abreu, Steven}, year = {2024}, eprint = {2407.12397}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, note = {Presented at ICML workshop ES-FOMO-II}, booktitle = {International Conference on Machine Learning (ICML) 2024 - ES-FOMO-II workshop}, } -
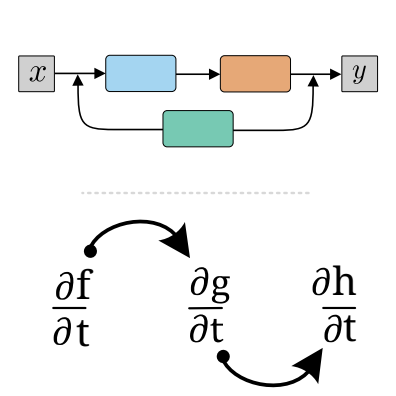 Neuromorphic Intermediate Representation: A Unified Instruction Set for Interoperable Brain-Inspired ComputingJens E. Pedersen*, Steven Abreu*, Matthias Jobst, and 12 more authorsNature Communications (in press), 2024
Neuromorphic Intermediate Representation: A Unified Instruction Set for Interoperable Brain-Inspired ComputingJens E. Pedersen*, Steven Abreu*, Matthias Jobst, and 12 more authorsNature Communications (in press), 2024Spiking neural networks and neuromorphic hardware platforms that emulate neural dynamics are slowly gaining momentum and entering main-stream usage. Despite a well-established mathematical foundation for neural dynamics, the implementation details vary greatly across different platforms. Correspondingly, there are a plethora of software and hardware implementations with their own unique technology stacks. Consequently, neuromorphic systems typically diverge from the expected computational model, which challenges the reproducibility and reliability across platforms. Additionally, most neuromorphic hardware is limited by its access via a single software frameworks with a limited set of training procedures. Here, we establish a common reference-frame for computations in neuromorphic systems, dubbed the Neuromorphic Intermediate Representation (NIR). NIR defines a set of computational primitives as idealized continuous-time hybrid systems that can be composed into graphs and mapped to and from various neuromorphic technology stacks. By abstracting away assumptions around discretization and hardware constraints, NIR faithfully captures the fundamental computation, while simultaneously exposing the exact differences between the evaluated implementation and the idealized mathematical formalism. We reproduce three NIR graphs across 7 neuromorphic simulators and 4 hardware platforms, demonstrating support for an unprecedented number of neuromorphic systems. With NIR, we decouple the evolution of neuromorphic hardware and software, ultimately increasing the interoperability between platforms and improving accessibility to neuromorphic technologies. We believe that NIR is an important step towards the continued study of brain-inspired hardware and bottom-up approaches aimed at an improved understanding of the computational underpinnings of nervous systems.
@article{pedersen2023neuromorphicintermediaterepresentationunified, title = {Neuromorphic Intermediate Representation: A Unified Instruction Set for Interoperable Brain-Inspired Computing}, author = {Pedersen, Jens E. and Abreu, Steven and Jobst, Matthias and Lenz, Gregor and Fra, Vittorio and Bauer, Felix C. and Muir, Dylan R. and Zhou, Peng and Vogginger, Bernhard and Heckel, Kade and Urgese, Gianvito and Shankar, Sadasivan and Stewart, Terrence C. and Eshraghian, Jason K. and Sheik, Sadique}, year = {2024}, journal = {Nature Communications (in press)}, } -
 PARSE-Ego4D: Personal Action Recommendation Suggestions for Egocentric VideosSteven Abreu, Tiffany D. Do, Karan Ahuja, and 4 more authorsunder review, 2024
PARSE-Ego4D: Personal Action Recommendation Suggestions for Egocentric VideosSteven Abreu, Tiffany D. Do, Karan Ahuja, and 4 more authorsunder review, 2024Intelligent assistance involves not only understanding but also action. Existing ego-centric video datasets contain rich annotations of the videos, but not of actions that an intelligent assistant could perform in the moment. To address this gap, we release PARSE-Ego4D, a new set of personal action recommendation annotations for the Ego4D dataset. We take a multi-stage approach to generating and evaluating these annotations. First, we used a prompt-engineered large language model (LLM) to generate context-aware action suggestions and identified over 18,000 action suggestions. While these synthetic action suggestions are valuable, the inherent limitations of LLMs necessitate human evaluation. To ensure high-quality and user-centered recommendations, we conducted a large-scale human annotation study that provides grounding in human preferences for all of PARSE-Ego4D. We analyze the inter-rater agreement and evaluate subjective preferences of participants. Based on our synthetic dataset and complete human annotations, we propose several new tasks for action suggestions based on ego-centric videos. We encourage novel solutions that improve latency and energy requirements. The annotations in PARSE-Ego4D will support researchers and developers who are working on building action recommendation systems for augmented and virtual reality systems.
@article{abreu2024parseego4dpersonalactionrecommendation, title = {PARSE-Ego4D: Personal Action Recommendation Suggestions for Egocentric Videos}, author = {Abreu, Steven and Do, Tiffany D. and Ahuja, Karan and Gonzalez, Eric J. and Payne, Lee and McDuff, Daniel and Gonzalez-Franco, Mar}, year = {2024}, eprint = {2407.09503}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, journal = {under review} } -
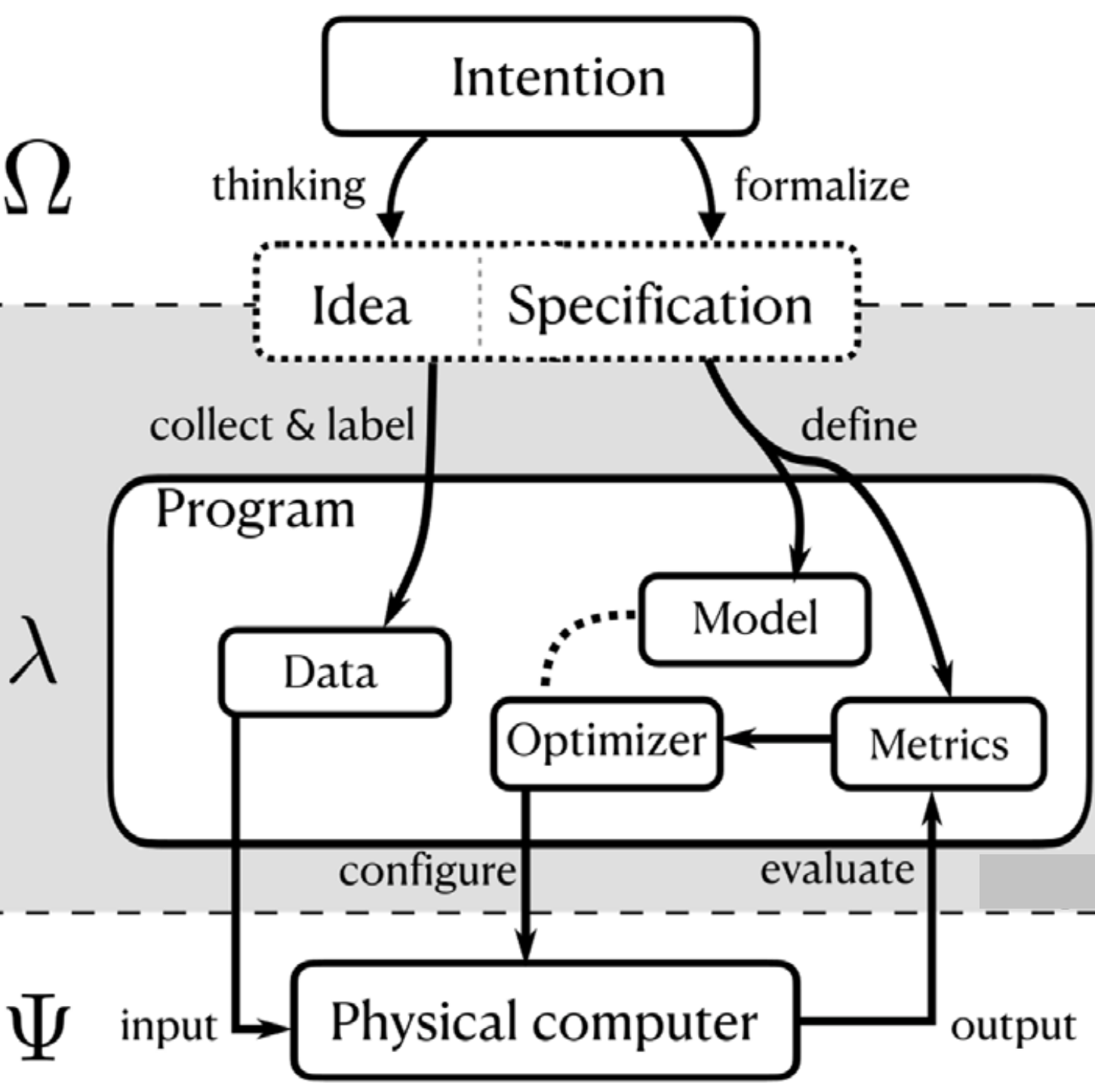 A photonics perspective on computing with physical substratesS. Abreu, I. Boikov, M. Goldmann, and 25 more authorsReviews in Physics, 2024
A photonics perspective on computing with physical substratesS. Abreu, I. Boikov, M. Goldmann, and 25 more authorsReviews in Physics, 2024We provide a perspective on the fundamental relationship between physics and computation, exploring the conditions under which a physical system can be harnessed for computation and the practical means to achieve this. Unlike traditional digital computers that impose discreteness on continuous substrates, unconventional computing embraces the inherent properties of physical systems. Exploring simultaneously the intricacies of physical implementations and applied computational paradigms, we discuss the interdisciplinary developments of unconventional computing. Here, we focus on the potential of photonic substrates for unconventional computing, implementing artificial neural networks to solve data-driven machine learning tasks. Several photonic neural network implementations are discussed, highlighting their potential advantages over electronic counterparts in terms of speed and energy efficiency. Finally, we address the challenges of achieving learning and programmability within physical substrates, outlining key strategies for future research.
@article{abreu2024photonics, title = {A photonics perspective on computing with physical substrates}, journal = {Reviews in Physics}, volume = {12}, pages = {100093}, year = {2024}, issn = {2405-4283}, doi = {https://doi.org/10.1016/j.revip.2024.100093}, author = {Abreu, S. and Boikov, I. and Goldmann, M. and Jonuzi, T. and Lupo, A. and Masaad, S. and Nguyen, L. and Picco, E. and Pourcel, G. and Skalli, A. and Talandier, L. and Vettelschoss, B. and Vlieg, E.A. and Argyris, A. and Bienstman, P. and Brunner, D. and Dambre, J. and Daudet, L. and Domenech, J.D. and Fischer, I. and Horst, F. and Massar, S. and Mirasso, C.R. and Offrein, B.J. and Rossi, A. and Soriano, M.C. and Sygletos, S. and Turitsyn, S.K.}, } -
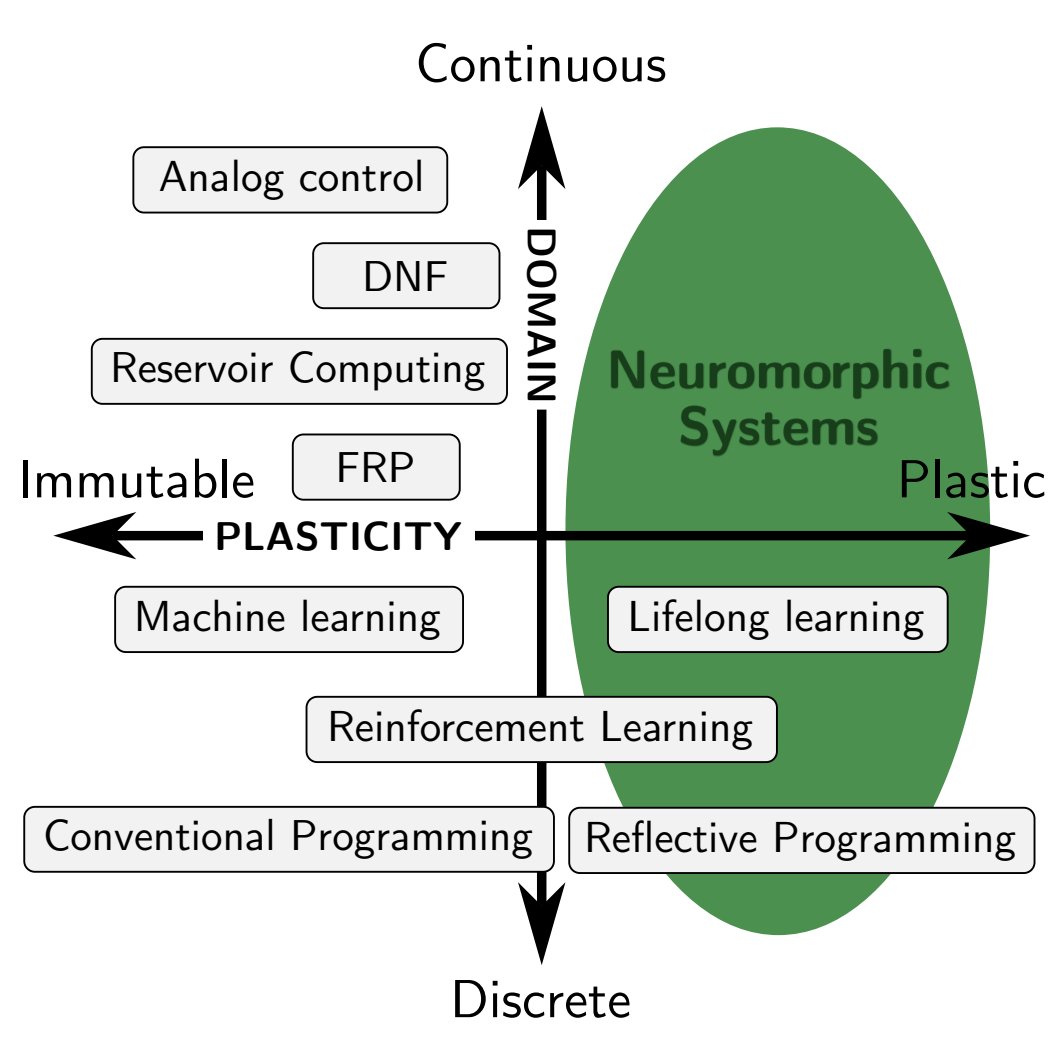 Neuromorphic Programming: Emerging Directions for Brain-Inspired HardwareSteven Abreu, and Jens E. PedersenIn Proceedings of the International Conference of Neuromorphic Systems, 2024
Neuromorphic Programming: Emerging Directions for Brain-Inspired HardwareSteven Abreu, and Jens E. PedersenIn Proceedings of the International Conference of Neuromorphic Systems, 2024The value of brain-inspired neuromorphic computers critically depends on our ability to program them for relevant tasks. Currently, neuromorphic hardware often relies on machine learning methods adapted from deep learning. However, neuromorphic computers have potential far beyond deep learning if we can only harness their energy efficiency and full computational power. Neuromorphic programming will necessarily be different from conventional programming, requiring a paradigm shift in how we think about programming. This paper presents a conceptual analysis of programming within the context of neuromorphic computing, challenging conventional paradigms and proposing a framework that aligns more closely with the physical intricacies of these systems. Our analysis revolves around five characteristics that are fundamental to neuromorphic programming and provides a basis for comparison to contemporary programming methods and languages. By studying past approaches, we contribute a framework that advocates for underutilized techniques and calls for richer abstractions to effectively instrument the new hardware class.
@inproceedings{AbreuPedersen2024, author = {Abreu, Steven and Pedersen, Jens E.}, title = {Neuromorphic Programming: Emerging Directions for Brain-Inspired Hardware}, year = {2024}, booktitle = {Proceedings of the International Conference of Neuromorphic Systems}, }
2023
-
 Flow Cytometry With Event-Based Vision and Spiking Neuromorphic HardwareSteven Abreu, Muhammed Gouda, Alessio Lugnan, and 1 more authorIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2023
Flow Cytometry With Event-Based Vision and Spiking Neuromorphic HardwareSteven Abreu, Muhammed Gouda, Alessio Lugnan, and 1 more authorIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2023Imaging flow cytometry systems play a critical role in the identification and characterization of large populations of cells or micro-particles. Such systems typically leverage deep artificial neural networks to classify samples. Here we show that an event-based camera and neuromorphic processor can be used in a flow cytometry setup to solve a binary particle classification task with less memory usage, and promising improvements in latency and energy scaling. To reduce the complexity of the spiking neural network, we combine the event-based camera with a free-space optical setup which acts as a non-linear high-dimensional feature map that is computed at the speed of light before the event-based camera receives the signal. We demonstrate, for the first time, a spiking neural network running on neuromorphic hardware for a fully event-based flow cytometry pipeline with 98.45 testing accuracy. Our best artificial neural network on frames of the same data reaches only 97.51, establishing a neuromorphic advantage also in classification accuracy. We further show that our system will scale favorably to more complex classification tasks. We pave the way for real-time classification with throughput of up to 1,000 samples per second and open up new possibilities for online and on-chip learning in flow cytometry applications.
@inproceedings{AbreuEtAl2023, author = {Abreu, Steven and Gouda, Muhammed and Lugnan, Alessio and Bienstman, Peter}, title = {Flow Cytometry With Event-Based Vision and Spiking Neuromorphic Hardware}, year = {2023}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops}, pages = {4138-4146}, }
2022
-
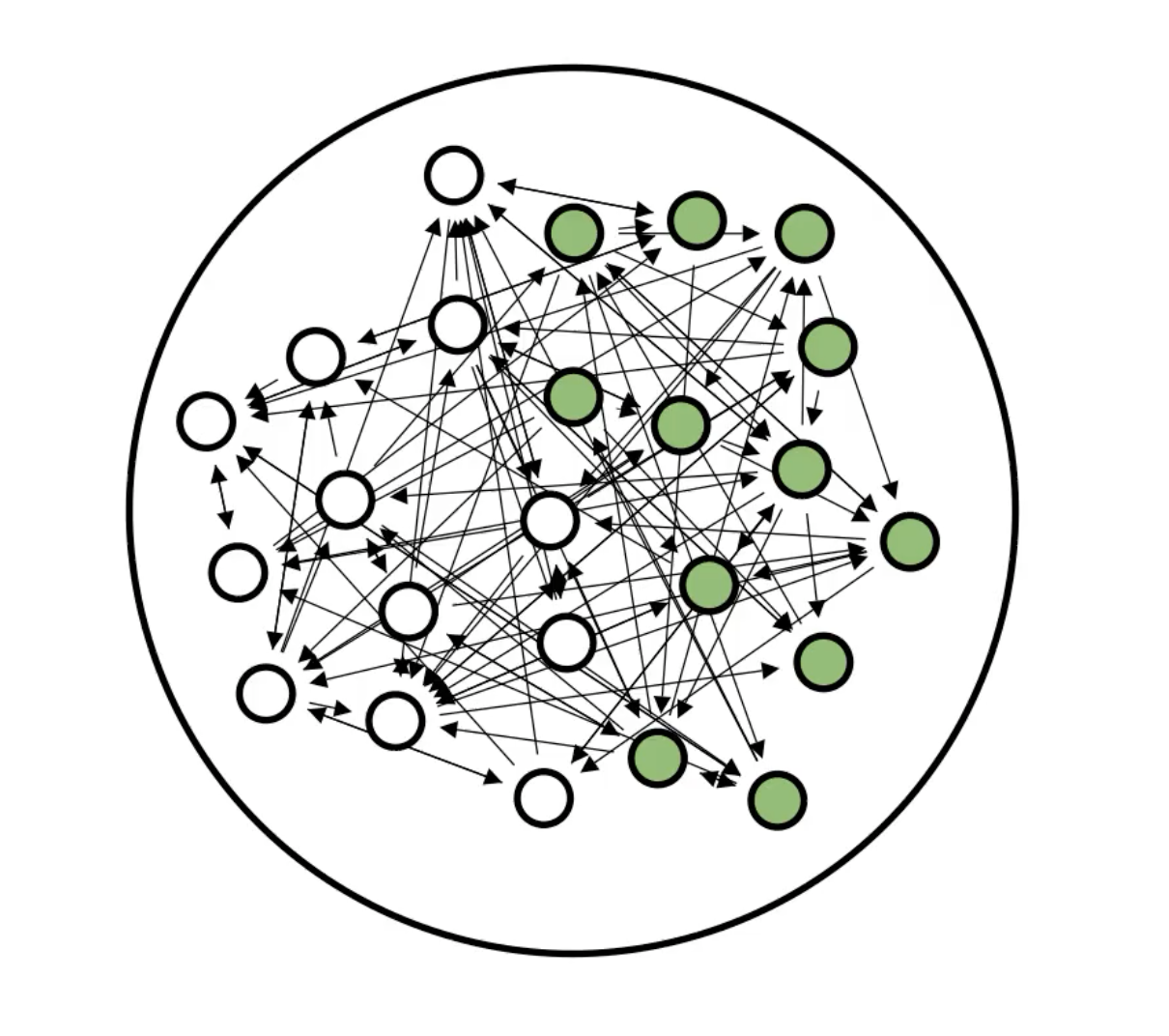 Hands-on reservoir computing: a tutorial for practical implementationMatteo Cucchi*, Steven Abreu*, Giuseppe Ciccone, and 2 more authorsNeuromorphic Computing and Engineering, 2022Accepted manuscript
Hands-on reservoir computing: a tutorial for practical implementationMatteo Cucchi*, Steven Abreu*, Giuseppe Ciccone, and 2 more authorsNeuromorphic Computing and Engineering, 2022Accepted manuscriptThis manuscript serves a specific purpose: to give readers from fields such as material science, chemistry, or electronics an overview of implementing a reservoir computing (RC) experiment with her/his material system. Introductory literature on the topic is rare and the vast majority of reviews puts forth the basics of RC taking for granted concepts that may be nontrivial to someone unfamiliar with the machine learning field. This is unfortunate considering the large pool of material systems that show nonlinear behavior and short-term memory that may be harnessed to design novel computational paradigms. RC offers a framework for computing with material systems that circumvents typical problems that arise when implementing traditional, fully fledged feedforward neural networks on hardware, such as minimal device-to-device variability and control over each unit/neuron and connection. Instead, one can use a random, untrained reservoir where only the output layer is optimized, for example, with linear regression. In the following, we will highlight the potential of RC for hardware-based neural networks, the advantages over more traditional approaches, and the obstacles to overcome for their implementation. Preparing a high-dimensional nonlinear system as a well-performing reservoir for a specific task is not as easy as it seems at first sight. We hope this tutorial will lower the barrier for scientists attempting to exploit their nonlinear systems for computational tasks typically carried out in the fields of machine learning and artificial intelligence. A simulation tool to accompany this paper is available online.
@article{CucchiEtAl2022handson, title = {Hands-on reservoir computing: a tutorial for practical implementation}, author = {Cucchi, Matteo and Abreu, Steven and Ciccone, Giuseppe and Brunner, Daniel and Kleemann, Hans}, year = {2022}, journal = {Neuromorphic Computing and Engineering}, note = {Accepted manuscript}, }
2019
-
 Automated architecture design for deep neural networksSteven AbreuArXiv, Aug 2019
Automated architecture design for deep neural networksSteven AbreuArXiv, Aug 2019Machine learning has made tremendous progress in recent years and received large amounts of public attention. Though we are still far from designing a full artificially intelligent agent, machine learning has brought us many applications in which computers solve human learning tasks remarkably well. Much of this progress comes from a recent trend within machine learning, called deep learning. Deep learning models are responsible for many state-of-the-art applications of machine learning. Despite their success, deep learning models are hard to train, very difficult to understand, and often times so complex that training is only possible on very large GPU clusters. Lots of work has been done on enabling neural networks to learn efficiently. However, the design and architecture of such neural networks is often done manually through trial and error and expert knowledge. This thesis inspects different approaches, existing and novel, to automate the design of deep feedforward neural networks in an attempt to create less complex models with good performance that take away the burden of deciding on an architecture and make it more efficient to design and train such deep networks.
@article{Abreu2019automated, author = {Abreu, Steven}, title = {Automated architecture design for deep neural networks}, year = {2019}, month = aug, journal = {ArXiv}, issue = {1908.10714}, archiveprefix = {arXiv}, eprint = {1908.10714}, }
1967
- Vision
 Letters on wave mechanicsAug 1967
Letters on wave mechanicsAug 1967@book{przibram1967letters, title = {Letters on wave mechanics}, author = {Einstein, Albert and Schrödinger, Erwin and Planck, Max and Lorentz, Hendrik Antoon and Przibram, Karl}, year = {1967}, publisher = {Vision}, }
1956
-
 Investigations on the Theory of the Brownian MovementAlbert EinsteinAug 1956
Investigations on the Theory of the Brownian MovementAlbert EinsteinAug 1956@book{einstein1956investigations, title = {Investigations on the Theory of the Brownian Movement}, author = {Einstein, Albert}, year = {1956}, publisher = {Courier Corporation}, }
1950
- The meaning of relativityAlbert Einstein, and AH TaubAmerican Journal of Physics, Aug 1950
@article{einstein1950meaning, title = {The meaning of relativity}, author = {Einstein, Albert and Taub, AH}, journal = {American Journal of Physics}, volume = {18}, number = {6}, pages = {403--404}, year = {1950}, publisher = {American Association of Physics Teachers} }
1935
- Can Quantum-Mechanical Description of Physical Reality Be Considered Complete?A. Einstein*†, B. Podolsky*, and N. Rosen*Phys. Rev., New Jersey. More Information can be found here , May 1935
In a complete theory there is an element corresponding to each element of reality. A sufficient condition for the reality of a physical quantity is the possibility of predicting it with certainty, without disturbing the system. In quantum mechanics in the case of two physical quantities described by non-commuting operators, the knowledge of one precludes the knowledge of the other. Then either (1) the description of reality given by the wave function in quantum mechanics is not complete or (2) these two quantities cannot have simultaneous reality. Consideration of the problem of making predictions concerning a system on the basis of measurements made on another system that had previously interacted with it leads to the result that if (1) is false then (2) is also false. One is thus led to conclude that the description of reality as given by a wave function is not complete.
@article{PhysRev.47.777, title = {Can Quantum-Mechanical Description of Physical Reality Be Considered Complete?}, author = {Einstein, A. and Podolsky, B. and Rosen, N.}, journal = {Phys. Rev.}, location = {New Jersey}, volume = {47}, issue = {10}, pages = {777--780}, numpages = {0}, year = {1935}, month = may, publisher = aps, doi = {10.1103/PhysRev.47.777}, url = {http://link.aps.org/doi/10.1103/PhysRev.47.777}, dimensions = {true}, }
1920
1905
- Über die von der molekularkinetischen Theorie der Wärme geforderte Bewegung von in ruhenden Flüssigkeiten suspendierten TeilchenA. EinsteinAnnalen der physik, May 1905
@article{einstein1905molekularkinetischen, title = {{\"U}ber die von der molekularkinetischen Theorie der W{\"a}rme geforderte Bewegung von in ruhenden Fl{\"u}ssigkeiten suspendierten Teilchen}, author = {Einstein, A.}, journal = {Annalen der physik}, volume = {322}, number = {8}, pages = {549--560}, year = {1905}, publisher = {Wiley Online Library}, } - Ann. Phys.Un the movement of small particles suspended in statiunary liquids required by the molecular-kinetic theory 0f heatA. EinsteinAnn. Phys., May 1905
@article{einstein1905movement, title = {Un the movement of small particles suspended in statiunary liquids required by the molecular-kinetic theory 0f heat}, author = {Einstein, A.}, journal = {Ann. Phys.}, volume = {17}, pages = {549--560}, year = {1905}, } - On the electrodynamics of moving bodiesA. EinsteinMay 1905
@article{einstein1905electrodynamics, title = {On the electrodynamics of moving bodies}, author = {Einstein, A.}, year = {1905}, } - Ann. Phys.Über einen die Erzeugung und Verwandlung des Lichtes betreffenden heuristischen GesichtspunktAlbert EinsteinAnn. Phys., May 1905
Albert Einstein receveid the Nobel Prize in Physics 1921 for his services to Theoretical Physics, and especially for his discovery of the law of the photoelectric effect
This is the abstract text.
@article{einstein1905photoelectriceffect, title = {{{\"U}ber einen die Erzeugung und Verwandlung des Lichtes betreffenden heuristischen Gesichtspunkt}}, author = {Einstein, Albert}, journal = {Ann. Phys.}, volume = {322}, number = {6}, pages = {132--148}, year = {1905}, doi = {10.1002/andp.19053220607}, }